
이 글은 Spring Batch의 Meta-Data Schema를 참고하여 작성하였으며, 개인적으로 스프링 배치에 사용하는 메타 테이블에 대해 공부하며 정리한 글입니다. 잘못된 내용이 있다면 짚어주시면 감사하겠습니다.
ERD
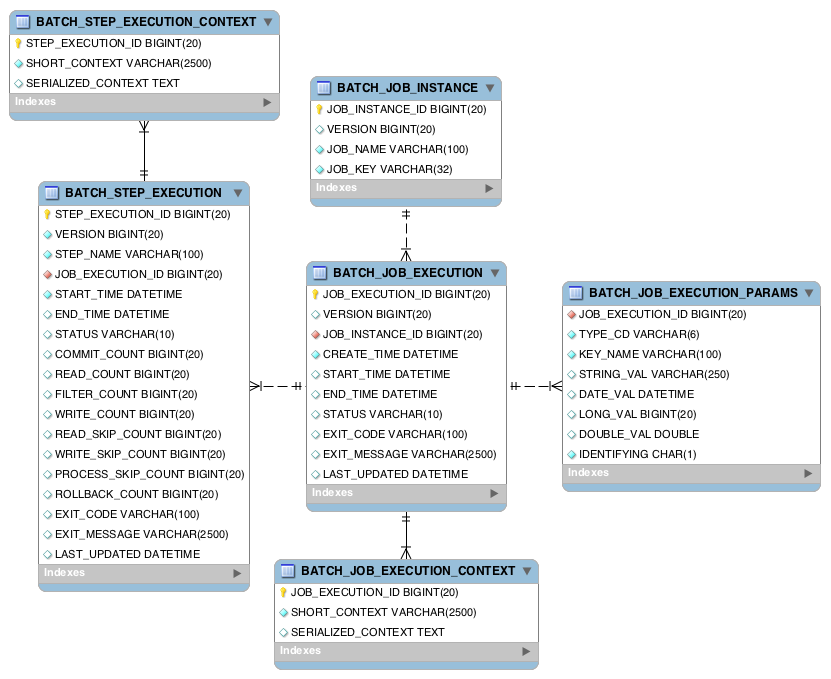
Spring Batch의 메타 데이터 테이블들은 배치의 도메인 객체들과 거의 정확히 일치한다. JobExecution와 BATCH_JOB_EXECUTION 테이블과 같이 말이다.
DDL 스크립트
- 이 메타 데이터 테이블의 DDL은
org.springframework.batch.core패키지 하위에 schema-*.sql 파일로 존재한다. 이때*는 지원하는 DB 이름이다. - 스프링 배치 버전 업으로 메타 데이터를 마이그레이션 해야 할 시
org/springframework/batch/code/migration하위 migration-*.sql스크립트를 이용하면 된다. 예를 들면 스프링 배치 버전 2.2 이전엔BATCH_JOB_EXECUTION_PARAMS테이블 대신BATCH_JOB_PARAMS테이블이 존재하였는데, 버전을 2.2 이상으로 올릴 시 DB마다BATCH_JOB_EXECUTION_PARAMS테이블로 데이터를 이전할 수 있는 마이그레이션 sql스크립트를 제공한다.
Version
메타 테이블 중 대부분이 version이라는 컬럼을 갖고 있다. 이 칼럼은 Spring Batch에서 메타 테이블 업데이트 시 사용할 낙관적 락을 위해 존재하며, 해당 레코드가 업데이트될 때마다 1씩 증가하며 동시성을 관리한다.
Identity
BATCH_JOB_INSTANCE, BATCH_JOB_EXECUTION, BATCH_STEP_EXECUTION은 _ID로 끝나는 컬럼을 가지며, 이 컬럼은 각 테이블의 주키 역할을 한다. 이 키 값은 DB에서 생성하는 값(database-generated key)이 아니며, 각자 개별의 sequence로부터 생성된 값이다. sequence를 사용하여 PK를 관리하는 이유로는 DB로부터 독립적인 값을 갖기 위해서인데, 만약 DB 드라이버가 변경되는 경우 마이그레이션 상황에 database-generated key가 달라질 수 있기 때문이다.
CREATE SEQUENCE BATCH_STEP_EXECUTION_SEQ;
CREATE SEQUENCE BATCH_JOB_EXECUTION_SEQ;
CREATE SEQUENCE BATCH_JOB_SEQ;오라클 DB와 같이 sequence가 지원되는 DB에는 위와 같은 sequence 생성문이 DDL 스크립트에 들어가 있지만, seqence가 없는 DB 벤더사에 대해서는 동일한 이름의 시퀀스 역할을 위한 테이블을 생성하여 처리한다.
CREATE TABLE BATCH_STEP_EXECUTION_SEQ (ID BIGINT NOT NULL) type=InnoDB;
INSERT INTO BATCH_STEP_EXECUTION_SEQ values(0);
CREATE TABLE BATCH_JOB_EXECUTION_SEQ (ID BIGINT NOT NULL) type=InnoDB;
INSERT INTO BATCH_JOB_EXECUTION_SEQ values(0);
CREATE TABLE BATCH_JOB_SEQ (ID BIGINT NOT NULL) type=InnoDB;
INSERT INTO BATCH_JOB_SEQ values(0);위와 같은 경우 테이블을 시퀀스처럼 사용하게 되는데, 예로 sequence가 없는 MySQL의 경우 Spring Core의 MySQLMaxValueIncrementer에서 컬럼을 1씩 증가시켜 기능적으로 테이블을 sequence와 동일하게 동작하도록 한다.
BATCH_JOB_INSTANCE
JobInstance 객체의 정보를 담고 있으며 Batch 계층 구조의 최상위에 위치한다.
CREATE TABLE BATCH_JOB_INSTANCE (
JOB_INSTANCE_ID BIGINT PRIMARY KEY ,
VERSION BIGINT,
JOB_NAME VARCHAR(100) NOT NULL ,
JOB_KEY VARCHAR(2500)
);JOB_KEY는 동일 Job 인스턴스를 고유하게 식별하기 위한 JobParameter의 직렬화 값이다.
BATCH_JOB_EXECUTION_PARAMS
JobParameter 객체의 정보를 담고 있다. Job 실행 시 사용된 파라미터를 저장하며, 정규화되지 않은 형태의 테이블인데 그 이유는 파라미터 타입에 대한 열이 별도로 존재하기 때문이다.
CREATE TABLE BATCH_JOB_EXECUTION_PARAMS (
JOB_EXECUTION_ID BIGINT NOT NULL ,
TYPE_CD VARCHAR(6) NOT NULL ,
KEY_NAME VARCHAR(100) NOT NULL ,
STRING_VAL VARCHAR(250) ,
DATE_VAL DATETIME DEFAULT NULL ,
LONG_VAL BIGINT ,
DOUBLE_VAL DOUBLE PRECISION ,
IDENTIFYING CHAR(1) NOT NULL ,
constraint JOB_EXEC_PARAMS_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
);TYPE_CD컬럼에서 저장되는 파라미터 타입을 가진다(STRING, DATE, LONG, DOUBLE). KEY_NAME은 파라미터 명이며 _VAL로 끝나는 컬럼들은 타입에 대한 값을 나타낸다. IDENTIFYING 컬럼은 각 JobInstance의 JOB_KEY를 생성하는 데 사용되는 여부이며, 사용되었다면 true의 값을 갖는다.
BATCH_JOB_EXECUTION
JobExecution 객체의 정보를 가지고 있다. 매 Job이 run 할 때, 항상 JobExecution이 생성되며 이 테이블의 row에 추가된다.
CREATE TABLE BATCH_JOB_EXECUTION (
JOB_EXECUTION_ID BIGINT PRIMARY KEY ,
VERSION BIGINT,
JOB_INSTANCE_ID BIGINT NOT NULL,
CREATE_TIME TIMESTAMP NOT NULL,
START_TIME TIMESTAMP DEFAULT NULL,
END_TIME TIMESTAMP DEFAULT NULL,
STATUS VARCHAR(10),
EXIT_CODE VARCHAR(20),
EXIT_MESSAGE VARCHAR(2500),
LAST_UPDATED TIMESTAMP,
JOB_CONFIGURATION_LOCATION VARCHAR(2500) NULL,
constraint JOB_INSTANCE_EXECUTION_FK foreign key (JOB_INSTANCE_ID)
references BATCH_JOB_INSTANCE(JOB_INSTANCE_ID)
) ;JOB 상태나 정보에 대한 컬럼들이 존재한다.
BATCH_STEP_EXECUTION
StepExecution 객체의 정보와 대응된다. BATCH_JOB_EXECUTION 테이블과 유사하며, 하나의 JobExecution에 대해 적어도 하나의 Step이 생성되고, 생성된 Step만큼 이 테이블의 row에 추가된다.
CREATE TABLE BATCH_STEP_EXECUTION (
STEP_EXECUTION_ID BIGINT PRIMARY KEY ,
VERSION BIGINT NOT NULL,
STEP_NAME VARCHAR(100) NOT NULL,
JOB_EXECUTION_ID BIGINT NOT NULL,
START_TIME TIMESTAMP NOT NULL ,
END_TIME TIMESTAMP DEFAULT NULL,
STATUS VARCHAR(10),
COMMIT_COUNT BIGINT ,
READ_COUNT BIGINT ,
FILTER_COUNT BIGINT ,
WRITE_COUNT BIGINT ,
READ_SKIP_COUNT BIGINT ,
WRITE_SKIP_COUNT BIGINT ,
PROCESS_SKIP_COUNT BIGINT ,
ROLLBACK_COUNT BIGINT ,
EXIT_CODE VARCHAR(20) ,
EXIT_MESSAGE VARCHAR(2500) ,
LAST_UPDATED TIMESTAMP,
constraint JOB_EXECUTION_STEP_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ;Step에 대한 상태 정보 등을 담고 있다. 재미있는 것은 Step을 구성하는 Reader, Processor, Writer에 대하여 처리한 item 수(READ_COUNT, PROCESS_SKIP_COUNT, WRITE_COUNT), commit-interval을 주어 나누어 처리했을 때 commit 한 개수(COMMIT_COUNT) 등을 담고 있기에, 실제 수행된 배치에서 처리한 개수 등을 알고 싶을 때 이 테이블을 찾아보면 된다.
BATCH_JOB_EXECUTION_CONTEXT
Job의 ExecutionContext와 대응된다. 정확히 하나의 JobExecution에 대하여 하나의 ExecutionContext가 존재하며, Job 레벨의 모든 데이터를 갖고 있다.
CREATE TABLE BATCH_JOB_EXECUTION_CONTEXT (
JOB_EXECUTION_ID BIGINT PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT CLOB,
constraint JOB_EXEC_CTX_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ;SHORT_CONTEXT 컬럼은 JobExecutionContext에 할당한 Map의 key-value 값들을 stringfy 하여 저장하고 있어, 원하는 대로 JobExecutionContext가 잘 세팅되었는지 확인할 수 있다.
BATCH_STEP_EXECUTION_CONTEXT
Step의 ExecutionContext에 대응된다. StepExecution과 StepExecutionContext는 일대일로 존재하며, 특정 stepExecution을 위한 모든 데이터를 포함하고 있다. 이 테이블은 추가적으로 JobInstance가 중단된 위치에서 다시 시작할 수 있도록 실패 후 검색되어야 하는 정보도 담고 있는 테이블이다.
CREATE TABLE BATCH_STEP_EXECUTION_CONTEXT (
STEP_EXECUTION_ID BIGINT PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT CLOB,
constraint STEP_EXEC_CTX_FK foreign key (STEP_EXECUTION_ID)
references BATCH_STEP_EXECUTION(STEP_EXECUTION_ID)
) ;SHORT_CONTEXT 컬럼은 StepExecutionContext 정보들을 담고 있다. JobInstance가 중단된 위치에서 재시작하기 위해 참고하는 데이터도 이 데이터일 것이다. 이는 확신은 아니지만 남은 데이터와 소스를 통해 유추할 수 있었다.
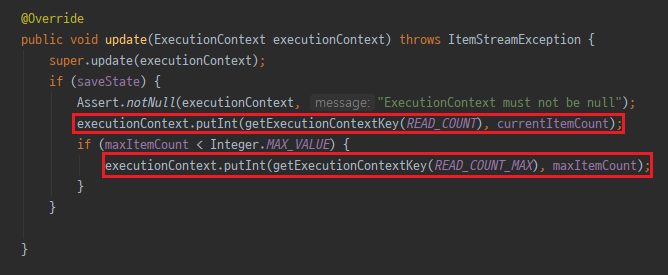
하나의 예로, AbstractItemCountingItemStreamItemReader는 READ_COUNT와 READ_COUNT_MAX를 갖는다.

그리고 BATCH_STEP_EXECUTION_CONTEXT 테이블 레코드를 업데이트할 때 현재까지 읽은 위치(READ_COUNT)와 최대 읽을 아이템 수(READ_COUNT_MAX) 값을 ExecutionContext에 저장(put)한다.
{
"CustomPagingItemReader.read.count":8844
"batch.taskletType":"org.springframework.batch.core.step.item.ChunkOrientedTasklet",
"batch.stepType":"org.springframework.batch.core.step.tasklet.TaskletStep"
}위는 값은 해당 StepExecution의 SHORT_CONTEXT 컬럼이며, {className}.read.count로 현재까지 읽은 currentItemCount가 기록된 것을 확인할 수 있다.
만약 Job이 중간에 실패되고 다시 시작하는 상황일 땐 어떨까? 초기화 시 AbstractItemCountingItemStreamItemReader의 open 메서드가 수행된다. 이때 READ_COUNT를 키로 StepExecutionContext를 조회한다. 테이블에 {className}.read.count 값이 있다면 이를 불러와 itemCount를 세팅하고, 이전 잡에서 읽었던 currentItemCount가 itemCount까지 되도록 Read 한 후(jumpToItem은 itemCount까지 만큼 read() 메서드를 수행한다) Job을 실행되도록 한다.



