WebFlux 전환
개인적으로 Spring WebFlux를 공부한 적은 있었지만, 실제 프로젝트에 적용해본 경험은 없었다. 그러던 중 사내 레거시로 서버를 재개발할 기회가 생겼고, 상황과 조건이 맞아 SpringMVC로 개발중이었던 프로젝트를 WebFlux로 전환하게 되었다. 또한, 부서 내에서 WebFlux 경험을 공유하는 자리를 가졌었는데 스스로 공부가 많이되었기에, 이렇게 블로그에도 남긴다.
WebFlux란?

WebFlux는 Spring 5에 새롭게 추가된 Reactive-stack의 웹 프레임워크이다.
WebFlux는 클라이언트와 서버에서 리액티브 애플리케이션 개발을 위한 논블로킹 리액티브 스트림을 지원한다.
WebFlux 논블로킹으로 동작하는 웹 스택의 필요성 때문에 등장하게 되었다. 기존 SpringMVC의 Servlet API는 v3.1 부터 논블로킹 I/O를 위한 API를 제공했었다. 하지만, 이외의 동기적으로 처리하는 모듈(Filter, Servlet)과 블로킹 방식의 API(getParameter, getPart)들이 있기에 완벽한 논블로킹 환경의 개발을 할 수 없었다. 또한, 비동기 논블로킹 환경의 서버로 Netty가 부상하고 있었으며 이 Netty와의 연동을 위해 Spring은 새로운 API가 필요했다.
WebFlux로의 전환 이유
SpringMVC로 개발하고 동작이 잘 되던 서버를 굳이 왜 WebFlux로 전환할까? 전환을 한다면 이에 대한 합리적인 이유가 필요하다. 그냥 새로운 기술이라, 적용하고 싶어서가 아니다.
먼저 SpringMVC와 WebFlux의 차이를 살펴보자
SpringMVC
SpringMVC는 하나의 요청에 대해 하나의 스레드가 사용된다(thread-per-request). 그렇기에 다수의 요청을 대비하여 미리 스레드 풀을 생성해놓으며, 각 요청마다 스레드를 할당하여 처리한다. 전통적인 방식의 서버는 이러한 방식으로 요청을 처리하는데 문제는 다음과 같은 상황에서 발생한다.
1) 블로킹 콜(Blocking Call)
동작중인 스레드가 블로킹 상태가 되면 다른 스레드에서 CPU 사용을 위해 문맥 교환(context switch)이 일어나게 된다. 만약 서버의 대부분의 연산이 이러한 블로킹 콜(blocking call)로 구성되어 있다면, 특히 MSA 환경은 API 호출 또는 db connection으로 대부분의 비즈니스 로직이 구성되어 있으니 잦은 문맥 교환이 일어나게 된다. 내부 블로킹 콜이 차지하는 비중만큼 문맥 교환의 오버헤드가 있는 것이다.
2) 많은 요청량(more and more request)
요청량이 증가한다면 스레드 수도 이에 비례하여 증가한다. 64비트 JVM은 기본적으로 스레드 스택 메모리를 1MB 예약 할당하는데 스레드 수가 증가한다면 서버가 감당해내지 못할 만큼의 메모리를 먹을 수 있다. 1만개 요청이면 9.76GB, 100만 개면 976GB 메모리를 점유한다 (불가능).
WebFlux
리액티브 프로그래밍은 논블로킹과 고정된 스레드 수 만으로 모든 요청을 처리함으로 위의 문제들을 해결한다. 논블로킹 리액티브 웹 스택 중 하나인 WebFlux는 위의 리액티브의 특징들을 가진다.
서버는 스레드 한 개로 운영하며, 디폴트로 CPU 코어 수 개수의 스레드를 가진 워커 풀을 생성하여 해당 워커 풀 내의 스레드로 모든 요청을 처리한다. 제약이 있다면 논블로킹으로 동작하여야만 하며, 블로킹 라이브러리가 필수적으로 사용되어야 한다면, 워커 스레드가 아닌 외부 별도의 스레드로 요청을 처리해야한다(이는 요청을 처리하는 Event Loop가 절대 블로킹되지 않아야 하기 때문이다).
전환이유
Spring WebFlux doc엔 굳이 잘 동작하는 SpringMVC 애플리케이션은 바꿀 필요가 없다고 한다. 그렇다면 왜 전환하게 되었는가.
우선 리액티브 애플리케이션이 가지는 이점 중 하나인 처리량을 얻고 싶었다. 서버 개수가 많아질 수록 관리할 장비가 많아지며, 아직 내가 고민할 단계는 아니지만 장비 개수는 예산과도 이어진다고 한다. 또한, 기술적 갈증(?)이 있었다...없었다면 거짓이다. 하지만 이외에도 고려할 조건들이 있었다.
1) 내부 작업의 유형
스프링 가이드에서는 내부 Hard한 연산들이 로직의 주를 이루는 경우 SpringMVC보다 성능적인 향상을 내지 못한다고 한다. 전환을 고려한다면 내부 로직들이 어떠한 연산으로 이루어져 있는지 고려할 필요가 있다. 내가 담당하던 서버는 내부 연산보다는 블로킹 콜인 파일 업다운로드와 외부 API 호출, db 조회가 주된 작업들로 이루어져 있었기에 WebFlux로의 전환이 성능적인 개선을 가져올 수 있는 구조였다.
2) 리액티브 라이브러리 유무
사용하는 라이브러리들이 블로킹이라면 이는 쉽게 논블로킹으로 전환하기 어려울 수 있다. 워커풀이 아닌 별도의 외부 스레드풀을 생성하여 논블로킹으로 처리할 수 있겠지만, 스프링 가이드는 최대한 이러한 방법도 피하는 것을 권장한다. 필자의 프로젝트엔 DB connection을 위해spring-boot-starter-data-mongodb 가 사용되고 있었고 MongoDB는 리액티브 라이브러리를 일찍 부터 제공 했었기에 dependency만 spring-boot-starter-data-mongodb-reactive 로 수정하여 리액티브 개발에 들어갈 수 있었다.
WebFlux 전환
절반정도 MVC로 개발하던 프로젝트를 WebFlux로 전환하며 겪었던 전환 요소나 결정해야 했던 상황들을 나열해본다.
Reactor - Reactive API
Reactor는 WebFlux에서 사용하는 리액티브 스트림 API의 구현체이다. 개발자가 리액티브 스트림을 직접 구현하는것은 매우 힘든일이며 이를 위해 Reactor는 고수준의 리액티브 API Mono와 Flux를 제공한다.
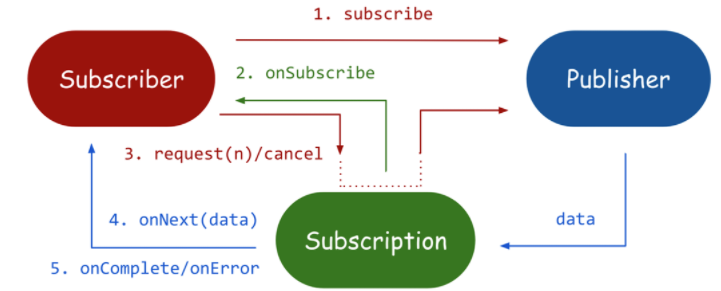
Mono는 0~1개의 데이터를 발행하는 Publisher 구현체이며, Flux는 0~N개의 데이터를 발행하는 Publisher 구현체이다.
Programming Model
MVC와 다르게 WebFlux는 두가지의 프로그래밍 모델이 존재한다.
Annotated Controller
SpringMVC와 같은 @Controller, @RequestMapping 애노테이션들을 활용한 방식의 프로그래밍 모델이다. 이 방법으로 택할 시, 변경할 사항이 가장 적었으며 MVC와 동일하게 spring-web 모듈의 애노테이션을 그대로 사용가능하다.
Functional Endpoints
WebFlux가 나오며 Spring에 추가된 프로그래밍 방식이다. 자바 8의 람다 표현식으로 자바에서 함수형 API를 작성할 수 있게되며, 이러한 방식으로 웹 서버를 개발할 수 있게 되었다. annotated controller와 다른 점으로는 애노테이션으로 의도를 선언하여 콜백받는 방식이 아닌, 요청을 애플리케이션이 처음부터 끝까지 다 제어한다(콜백받기 위해 애노테이션을 scan, mapping 과정이 생략되어서인지 애플리케이션 부팅 시간이 좀 더 빠르다 한다).
필자의 프로젝트는 MVC기반으로 작성되었었고 첫 WebFlux로의 전환이기에 Annotated Controller 방식을 선택하였다.
설정
MVC의 경우 WebMvcConfigurer를 implements하고 원하는 추가 설정은 오버라이드하여 구현한다. WebFlux의 경우에도 크게 다르지 않다. WebFluxConfigurer를 implements하고 동일하게 원하는 설정을 오버라이드하여 구현하면 된다.
필터와 인터셉터
WebFlux는 필터와 인터셉터의 기능을 WebFliter 클래스로 제공한다. 인증과 Acl을 위해 구현되었던 인터셉터를 WebFliter로 전환하였다.
코드
리턴 타입 변환 T → Mono, Flux
컨트롤러와 서비스 메소드에서의 리턴 타입을 전환하였다. 기존에 일반 타입으로 반환하였다면, Reactor는 리액티브 스트림을 지원하는 Mono와 Flux를 제공하기에 리턴 타입도 Mono, Flux로 전환되어야 한다.
리액티브 라이브러리의 경우 이미 Mono와 Flux의 리턴타입을 가질것이며, 직접 데이터를 생성하는 경우라면 just() 메서드로 감싸서 전달하도록 한다.
비동기 작업의 순서유지를 위해 flatMap으로 체이닝
WebFlux 전환 시, 내부엔 블로킹이 존재하지 않는다. 작업들은 비동기적으로 처리될 것이며 라인 순서에 따른 실제 코드의 동작 순서는 일치하지 않게된다(메서드를 호출해도 실제 동작은 나중에 처리될것이기 때문이다). 이때 flatMap을 통해 이전 비동기 작업이 끝난 후 다음 로직들이 처리되도록 순서를 보장시켜줄 수 있다.
내부가 동기적인 동작이라면 map으로 체이닝
flatMap과 map의 차이점은 전달하는 함수의 리턴 타입이다. flatMap에 전달하는 함수의 리턴 타입은 Mono나 Flux와 같은 리액티브 API이며, 이는 비동기 동작이 있는 함수를 전달하기 위해서이다.

하지만, 블로킹될 일이 없는 로직으로만 구성되고 데이터를 직접 생성한다면 map 함수를 통해 체이닝 할 수 있다. 그렇기에 map에 전달하는 함수는 일반적인 오브젝트(T)를 리턴 한다

예외처리는 Mono.error(Throwable), onErrorXX로
WebFlux에서 리턴 타입은 Mono나 Flux로 구성된다. 그렇기에 예외를 던져야할 때 throw 대신 Mono.error API를 사용하자. Mono.error를 리턴 시키도록 수정하고 던지던 예외는 error() 메서드에 인자로 전달한다.
예외 처리 시 Exception을 발생시키는 것 이외에도 catch 실패 시 처리할 로직을 태울때도 있다. 그런경우는 onErrorXX API를 사용하자. 이는 예외 발생 시 다른 Mono나 Flux 형태로 리턴하여 반환할 수 있도록 한다.
블로킹 라이브러리
어쩔수 없이 블로킹 라이브러리가 사용되어야 한다면 별도의 스레드 풀을 생성하여 이를 이용해야한다. 찾아보니 publishOn 연산자를 통해 연산을 다른 스레드 풀로 전환하여 사용할 수 있다고 하는데, 필자와 같은 경우 ThreadPoolTaskExecutor을 통해 별도의 스레드 풀을 생성하고 필요한 작업만을 할당하게 하였다.
CompletableFuture::supplyAsync 를 통해 필요한 작업을 특정 executor(별도로 만든 스레드 풀)에 할당하여 처리하도록 하였으며

Mono::fromFuture로 생성된 CompletableFuture를 Mono로 전환하였다.

위와 같은 방법으로 필요한 작업만을 외부 라이브러리에서 동작할 수 있도록 해주었다.
Blocking Call 검출
리액티브 애플리케이션에서의 블로킹 콜은 매우 치명적이다. 그렇기에 BlockHound 사용하여 내부 블로킹 콜을 검출할 수 있다.
BlockHound는 논블로킹으로 동작해야만 하는 스레드에 대해 블로킹 콜을 감지하며 예외를 발생시킨다. 이때 논블로킹으로 동작해야만 하는 스레드는 서버 역할의 하나의 메인 스레드와 CPU 코어 수 만큼 생성하는 워커 스레드들을 의미한다.
적용도 pom.xml에 dependency를 추가해주고
<dependencies>
<dependency>
<groupId>io.projectreactor.tools</groupId>
<artifactId>blockhound</artifactId>
<version>$LATEST_RELEASE</version>
</dependency>
</dependencies>애플리케이션 시작시 BlockGound.install을 호출해 주기만 하면 BlockHound가 적용 된다.
BlockHound 사용시 주의할 점이라면 스레드에서 블로킹 콜 여부를 감시하기 때문에 개발 환경이 아닌 리얼 환경에서 사용한다면 성능에 영향을 미치게된다. 그렇기에 개발 환경에서 적용하여 블로킹 콜이 없는지 최대한 테스트하고 리얼 환경에선 이 라이브러리를 사용하지 않도록 하자.